ad

概要
クラウドのAIを契約するほどではなかったり、だけど企業情報とかアップロード出来なかったりするとき、Local LLMでSlackからAI使えたらどうかなという実験で構築しました。
実験なので、ブラッシュアップしたら随時更新します。
構築環境
Pythonを使います。バージョンは3.12
利用するモジュールは
slack-bolt、requests
の2つです。
.venvで構築作業で説明しますシンプルなのでほかの環境でも問題ないかと思います。
アプリの設定
local llmはOllamaを通じて利用します。
Ollamaをインストールして、任意のLLMをインストールしておいてください。
ここでは「translategemma:4b」をインストールして使います。
https://ollama.com/
Slack側にボットとAPIの準備が必要です。
Slack API側の設定(最重要ポイント)
外部から自宅PCにアクセスさせるのではなく、自宅PCからSlackに「繋ぎにいく」Socket Modeを利用します。
① アプリの作成
② 権限の設定
③ Socket Modeとイベントの有効化
コード
WIndowsにPython 3.12がインストールされていることを前提に作業します。
インストールしていない場合は公式サイトからインストールしてください。
カレントユーザのドキュメントフォルダ内にプロジェクトフォルダを作成し、Pythonの仮想環境を作成します。
cd ~\documents
mkdir local-llm-slackbot
cd local-llm-slackbot
py -3.12 -m venv venv次に.venv環境をアクティブにして、Slack公式のフレームワークと、HTTPリクエスト用のライブラリをインストールします
.\venv\Scripts\activate
py -m pip install --upgrade pip
pip install slack-bolt requests
deactivate
explorer .最後のコマンドでlocal-llm-slackbotのフォルダが開いています。
このフォルダへapp.pyを作成して、次のコードを貼りつけ、Slackの2つのTokenをコピペしてください。
Tokenは冒頭のアルファベットがポイントです。
SLACK_BOT_TOKEN は、xoxbで始まる
SLACK_APP_TOKEN は、xappで始まる
OLLAMA_MODEL ここではollama経由で利用するLLMのモデル名をOllamaで表示されている通りに入力してください。利用時にはTerminalから起動します。
import requests
from slack_bolt import App
from slack_bolt.adapter.socket_mode import SocketModeHandler
# ==========================================
# 1. トークンの宣言(ここを書き換えてください)
# ==========================================
SLACK_BOT_TOKEN = "xoxb-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
SLACK_APP_TOKEN = "xapp-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
OLLAMA_MODEL = "translategemma:4b" # 使用するモデル名
# Appの初期化
app = App(token=SLACK_BOT_TOKEN)
# ==========================================
# 2. 履歴管理用の辞書
# { "ユーザーID": [メッセージ履歴のリスト] }
# ==========================================
user_histories = {}
@app.event("app_mention")
def handle_mention(event, say):
user_id = event['user']
# メンション部分(<@U...>)を除去して純粋な質問文を取得
raw_text = event['text']
user_query = raw_text.split('> ')[-1] if '> ' in raw_text else raw_text
# そのユーザーの履歴がなければ初期化
if user_id not in user_histories:
user_histories[user_id] = []
# ユーザーの質問を履歴に追加
user_histories[user_id].append({"role": "user", "content": user_query})
# デバッグ用:誰が話しかけてきたかターミナルに表示
print(f"User {user_id} says: {user_query}")
# Ollamaへのリクエスト
try:
# 履歴全体をmessagesとして投げることで「前後の文脈」を理解させる
response = requests.post(
'http://localhost:11434/api/chat',
json={
"model": OLLAMA_MODEL,
"messages": user_histories[user_id],
"stream": False
},
timeout=60 # 応答待ち時間を設定
)
response.raise_for_status()
# AIの回答を取得
result = response.json()
answer = result.get('message', {}).get('content', "申し訳ありません、回答を生成できませんでした。")
# AIの回答も履歴に追加(次回の会話の文脈になる)
user_histories[user_id].append({"role": "assistant", "content": answer})
# 【トークン節約とメモリ管理】
# 履歴が長くなりすぎるとVRAMを圧迫し、推論が遅くなるため、直近10往復分に制限
if len(user_histories[user_id]) > 20:
user_histories[user_id] = user_histories[user_id][-20:]
# Slackへ返信
say(f"<@{user_id}> \n{answer}")
except Exception as e:
error_msg = f"エラーが発生しました: {str(e)}"
print(error_msg)
say(error_msg)
# ==========================================
# 3. 実行
# ==========================================
if __name__ == "__main__":
print(f"⚡️ Bolt app is running with model: {OLLAMA_MODEL}")
handler = SocketModeHandler(app, SLACK_APP_TOKEN)
handler.start()使い方
Terminalを開く
ollamaでモデルを起動し、アプリを起動します。
ollama run translategemma:4bollamaのTerminalは開いたまま、
新しくTeminalを開きアプリを起動する
cd ~\documents\local-llm-slackbot
.\venv\Scripts\activate
python app.pyアプリが起動するとTerminalには次のような Bolt app is running!と表示されます。
これでSlack側からPCのlocal llmを使ったSlack botと会話できます。

Slackのチャンネルでチャンネルへ作成したbotを招待します。
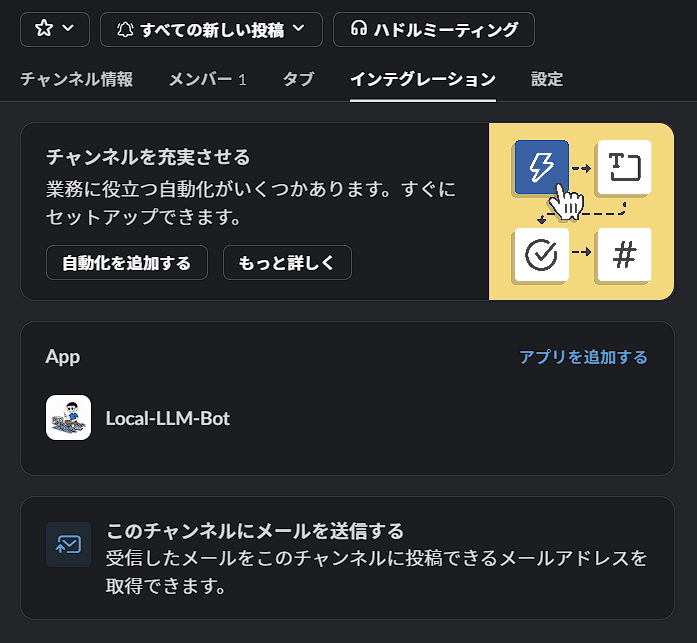
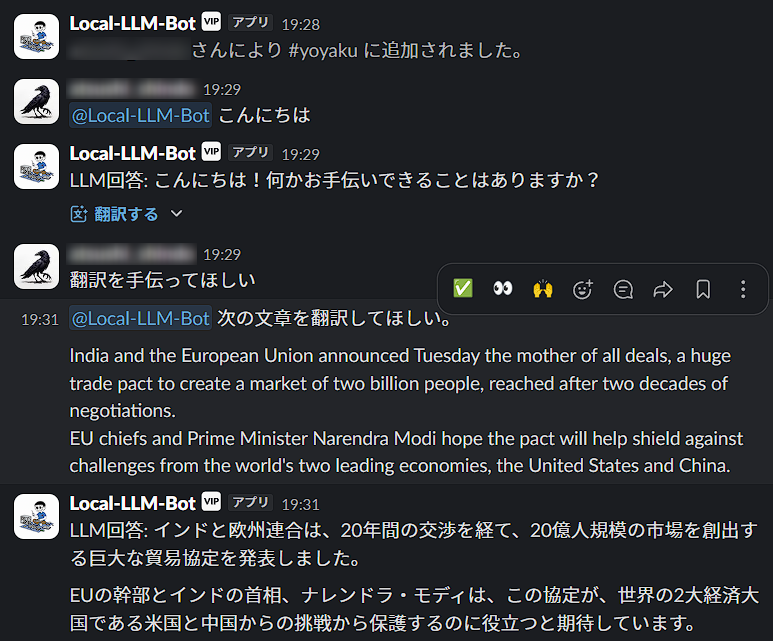
メンションを付けて会話すると、応答してくれます。
このモデル translategemma:4bは量子化が4bitなので、比較的GPUのRAM消費も少なくすみます。そのうえ、翻訳に特化していますので翻訳は良い内容です。また、スクリプトではユーザーごとに対応するよう設定しています。
ollamaを終了する時はTerminalで
ollama /byeアプリの終了は、コントロールキー+Cで.venv環境へ戻ります。
ad