目次
ad
概要
前回PCローカル環境へWhisperを使った文字起こしアプリを作りました。今回は話者毎に分離してみます。分離とは話者名ではありませんが、スピーカーA,B,Cなどに分け、タイムラインを付加する形です。議事録をまとめる時や字幕を扱う時には便利かもしれません。
今回は少し登録が必要ですが次の機械学習モデルを使います。
“Hugging Face” 機械学習版GitHubというような共有の場で、機械学習モデルをHugging Faceからも提供されており、学習目的など非営利利用は無料で使える部分があります。
前回の投稿は下記のリンクから参照ください。前回のセットアップが完了している状態から機能を追加します。


作業概要
Gitのインストール
Hugging Faceへサインアップ(アカウント作成)
機械学習モデルのインストール
Webアプリの新規作成
動作テスト
手順
前回作成した環境は次のようなフォルダ構成になっているとします
今回はvenvフォルダの配下にmodelsというフォルダを作成しmodelsフォルダへ学習モデルを新たにインストールします。最後に作るPythonの実行ファイルにはこのフォルダ構成で設計してPATH指定もしていますのでフォルダ階層は忠実に作る必要があります。
C:\Users\hoge\Documents\WhisPy\
├─ venv\
├─ web.py
└─ (他に readme や bat ファイルなど)
Gitのインストール
前回の手順ではchocolateyをインストールしてあります。gitも次のコマンドでインストールします。インストール後はPowershell or Terminalは再起動します。
choco install gitad
Hugging Faceへサインアップ
サインアップと必要な設定は次の手順です。
- https://huggingface.co/ へアクセス
- Email Addressと任意のパスワードを入力してNext
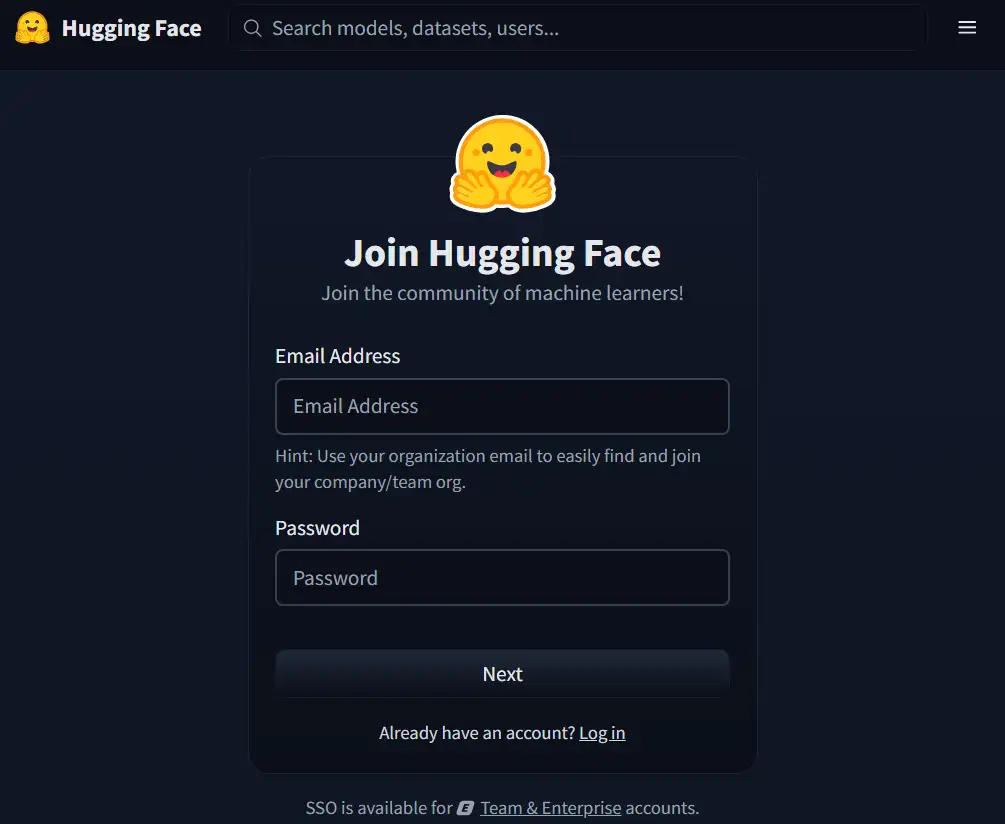
- 必須項目だけ入力してください。optionalは入力しなくて良いです。
- 設定したメールアドレスへ確認メールが届きます。
確認メールにあるリンクをクリックして設定を完了させてください。 - https://huggingface.co/pyannote/speaker-diarization-community-1/ へアクセス
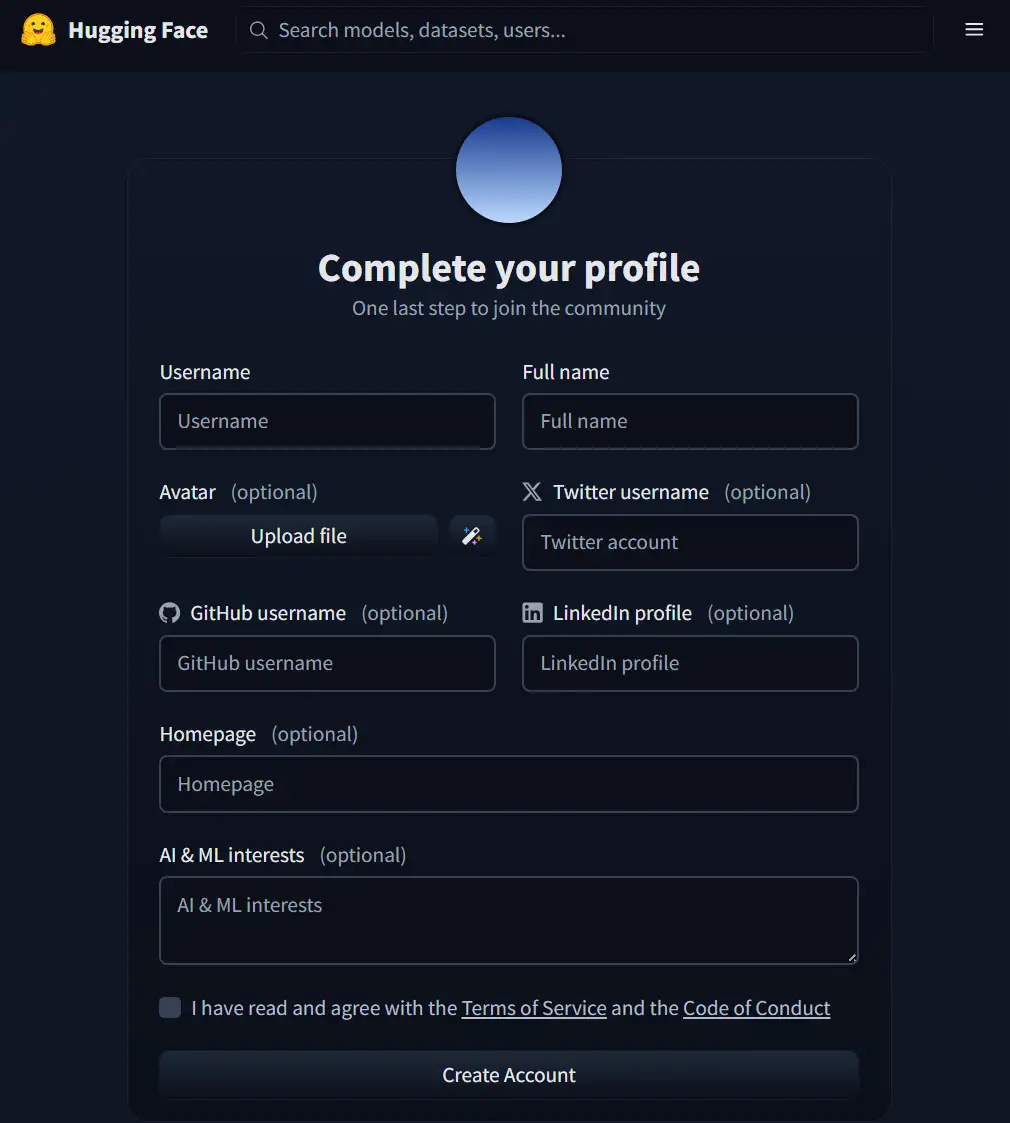
- Company/university、Use caseを入力して Agree and access repository をクリック
- 画面の右上のメニューから Settingsを開く
- Access Tokensを表示
- Token type は Readを選択、Token nameは任意で入力、Create tokenをクリック
- 表示されたAccess Tokenはどこか流出しないような場所へコピペで保存しておきます。
これでHugging Faceの準備は完了
あ、説明省きますが、Authentication でTwo-Factorのセキュリティ設定はしましょう。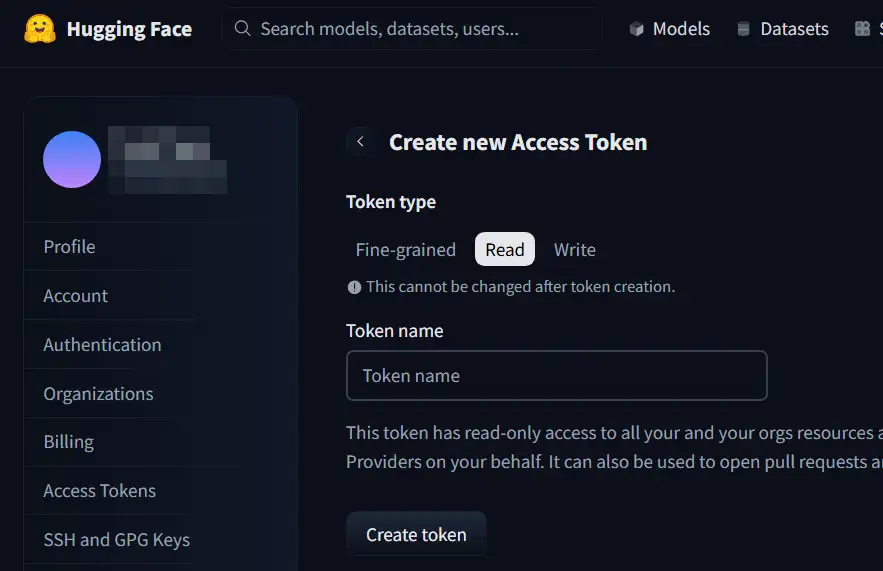
機会学習モデルのインストール
フォルダ名 models を作ります
cd ~\documents\WisPymkdir modelsターミナルでmodelsフォルダまで移動します。
cd ~\documents\WispPy\models続いて、二つのコマンドを実行する
git lfs installgit clone https://hf.co/pyannote/speaker-diarization-community-1 ./pyannote-speaker-diarization-community-1認証情報を求められます。
cloneで指定しているのはHugging Faceのgitです。
Hugging Faceで設定したUsername これは、Hugging FaceでSettings > Account情報画面で確認が出来る。Passwordは、作成したAccess Tokenです。
入力し、Continueするとcloneが開始されます。
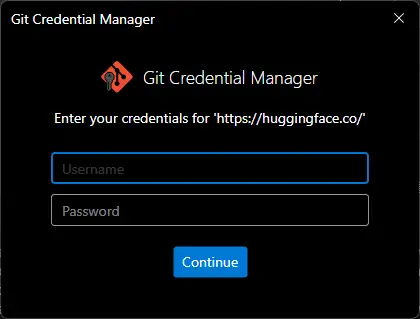
補足、Terminal実行で入力するようなgitの認証情報はWindowsの資格情報マネジャーへ保存されます。コントロールパネル > 資格情報マネジャー > Windows 資格情報を表示すると、一覧の中に git:https:\\huggingface.co という情報が保存されているはずです。もし誤った情報が保存されたり、Tokenを変更した場合はここから削除すると再度入力が可能です。
ad
Webアプリの新規作成
venvフォルダ配下に web2.pyを作成し次のコードを保存します。
#!/usr/bin/env python3
"""
Whisper 文字起こし Web アプリ
(Streamlit・Windows 向け・設定をメイン画面に表示・話者分離オプション付き・モデル完全ローカル)
"""
import os
import time
import tempfile
from datetime import datetime
import streamlit as st
import torch
import whisper
# ===== pyannote.audio の有無チェック =====
try:
from pyannote.audio import Pipeline # type: ignore
HAVE_PYANNOTE = True
except ImportError:
HAVE_PYANNOTE = False
# ===== torchaudio の有無チェック(AudioDecoder 回避のために使う) =====
try:
import torchaudio # type: ignore
HAVE_TORCHAUDIO = True
except ImportError:
HAVE_TORCHAUDIO = False
# ===== パス設定(app.py と同じ階層に models フォルダを置く前提) =====
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
PYANNOTE_MODEL_DIR = os.path.join(
BASE_DIR, "models", "pyannote-speaker-diarization-community-1"
)
# ===== 結果保持用のセッション状態を初期化 =====
if "transcript_text" not in st.session_state:
st.session_state["transcript_text"] = ""
if "transcript_meta" not in st.session_state:
st.session_state["transcript_meta"] = {}
if "labeled_segments" not in st.session_state:
st.session_state["labeled_segments"] = None
if "last_filename" not in st.session_state:
st.session_state["last_filename"] = ""
# ページ設定
st.set_page_config(
page_title="Whisper文字起こしツール",
page_icon="🔊",
layout="wide",
)
@st.cache_resource
def load_whisper_model(model_name: str):
"""Whisper モデルをロード(キャッシュあり)"""
device = "cuda" if torch.cuda.is_available() else "cpu"
return whisper.load_model(model_name, device=device)
@st.cache_resource
def load_diarization_pipeline():
"""
pyannote.audio の話者分離パイプラインをロード(キャッシュあり)
モデルは Hugging Face から git clone 済みのローカルディレクトリから読み込みます。
"""
if not HAVE_PYANNOTE:
raise RuntimeError("pyannote.audio がインストールされていません。")
if not os.path.isdir(PYANNOTE_MODEL_DIR):
raise RuntimeError(
"pyannote モデルディレクトリが見つかりませんでした。\n"
f"想定パス: {PYANNOTE_MODEL_DIR}\n"
"venv 内の models フォルダに次のように clone しておいてください:\n"
" git lfs install\n"
" git clone https://huggingface.co/pyannote/speaker-diarization-community-1 "
"models/pyannote-speaker-diarization-community-1"
)
pipeline = Pipeline.from_pretrained(PYANNOTE_MODEL_DIR)
if torch.cuda.is_available():
pipeline.to(torch.device("cuda"))
return pipeline
def check_ffmpeg():
"""FFmpeg がインストールされているか確認(Windows 用に NUL を使用)"""
if os.system("ffmpeg -version > NUL 2>&1") != 0:
st.error(
"⚠️ FFmpeg がインストールされていません。\n"
" 例: 管理者権限の PowerShell で `choco install ffmpeg` を実行してから、\n"
" ターミナルを開き直して再度お試しください。chocolatey がインストールされている場合の例です。"
)
st.stop()
def get_available_models():
"""選択可能な Whisper モデル一覧"""
return ["tiny", "base", "small", "medium", "large"]
def format_timestamp(seconds: float) -> str:
"""秒を H:MM:SS.mmm 形式に変換"""
dt = datetime.utcfromtimestamp(seconds)
return dt.strftime("%H:%M:%S.%f")[:-3]
def attach_speakers_to_whisper_segments(segments, diarization):
"""
Whisper のセグメントそれぞれに話者ラベルを付与する簡易実装。
- 各 Whisper セグメントの「中点の時刻」が、
pyannote のどの話者区間に含まれるかで話者を決める。
"""
labeled = []
# pyannote.audio 4.x の DiarizeOutput と 3.x の Annotation 両対応
if hasattr(diarization, "speaker_diarization"):
annotation = diarization.speaker_diarization
else:
annotation = diarization
diar_segments = []
for turn, _, speaker in annotation.itertracks(yield_label=True):
diar_segments.append(
{
"start": float(turn.start),
"end": float(turn.end),
"speaker": str(speaker),
}
)
for seg in segments:
start = float(seg["start"])
end = float(seg["end"])
mid = 0.5 * (start + end)
speaker_label = "UNKNOWN"
for ds in diar_segments:
if ds["start"] <= mid <= ds["end"]:
speaker_label = ds["speaker"]
break
new_seg = dict(seg)
new_seg["speaker"] = speaker_label
labeled.append(new_seg)
return labeled
def main():
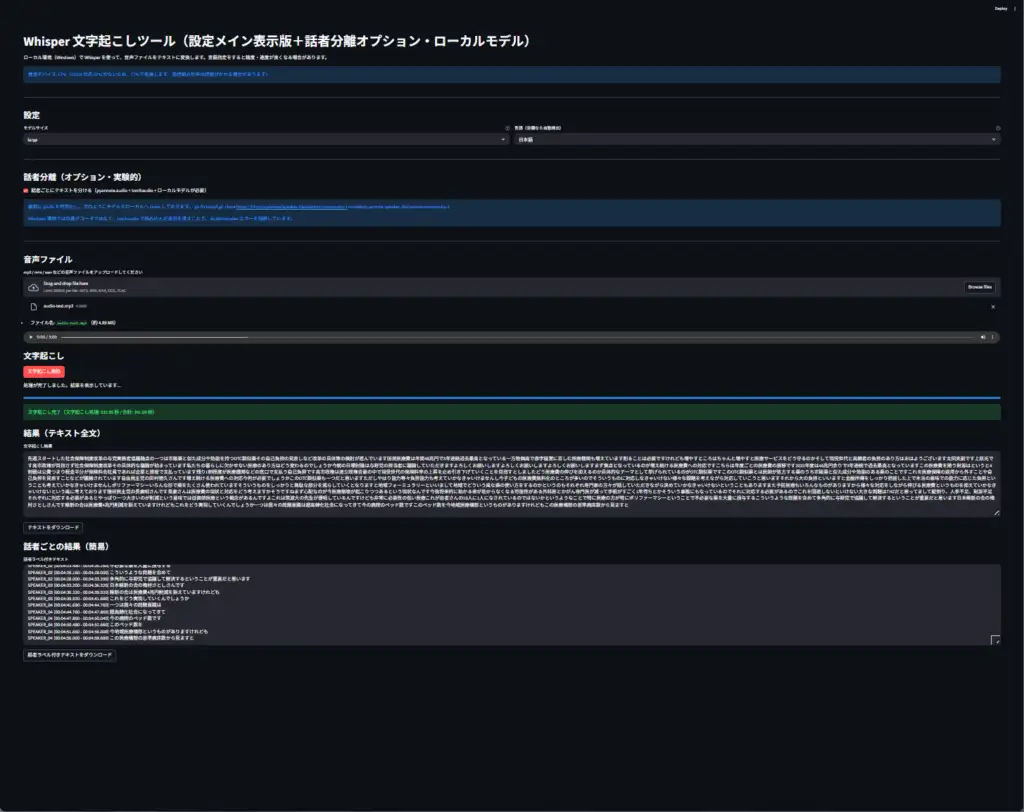
st.title("Whisper 文字起こしツール(設定メイン表示版+話者分離オプション・ローカルモデル)")
st.write(
"ローカル環境(Windows)で Whisper を使って、音声ファイルをテキストに変換します。"
"言語指定をすると精度・速度が良くなる場合があります。"
)
# FFmpeg の確認
check_ffmpeg()
# デバイス情報
if torch.cuda.is_available():
device_label = "GPU (CUDA)"
st.info(f"使用デバイス: {device_label}")
else:
device_label = "CPU"
st.info(
f"使用デバイス: {device_label}(CUDA 対応 GPU がないため、CPUで処理します。長時間の音声は時間がかかる場合があります)"
)
st.markdown("---")
# ===== 設定エリア =====
st.subheader("設定")
col1, col2 = st.columns(2)
with col1:
model_name = st.selectbox(
"モデルサイズ",
options=get_available_models(),
index=1, # base をデフォルト
help="大きいモデルほど精度は上がりますが、処理時間とメモリ使用量も増えます。",
)
with col2:
language_code = st.selectbox(
"言語(空欄なら自動検出)",
options=["", "en", "ja", "zh", "de", "fr", "es", "ko", "ru"],
index=0,
format_func=lambda x: {
"": "自動検出",
"en": "英語",
"ja": "日本語",
"zh": "中国語",
"de": "ドイツ語",
"fr": "フランス語",
"es": "スペイン語",
"ko": "韓国語",
"ru": "ロシア語",
}.get(x, x),
help="音声の言語が分かっている場合は指定すると精度・速度が安定します。",
)
# ===== 話者分離オプション =====
st.markdown("---")
st.subheader("話者分離(オプション・実験的)")
use_diarization = st.checkbox(
"話者ごとにテキストを分ける(pyannote.audio + torchaudio + ローカルモデルが必要)",
value=False,
)
if use_diarization:
if not HAVE_PYANNOTE:
st.error(
"pyannote.audio がインストールされていません。\n"
" 例: 仮想環境内で `pip install pyannote.audio` を実行してください。"
)
if not HAVE_TORCHAUDIO:
st.error(
"torchaudio がインストールされていません。\n"
" 例: 仮想環境内で `pip install torchaudio` を実行してください。"
)
st.info(
"事前に git-lfs を有効化し、次のようにモデルをローカルへ clone しておきます。\n"
" git lfs install\n"
" git clone https://huggingface.co/pyannote/speaker-diarization-community-1\n"
" models/pyannote-speaker-diarization-community-1\n\n"
"Windows 環境では内蔵デコーダではなく、torchaudio で読み込んだ波形を渡すことで、\n"
"AudioDecoder エラーを回避しています。"
)
st.markdown("---")
# ===== 音声ファイルアップロード =====
st.subheader("音声ファイル")
uploaded_file = st.file_uploader(
"mp3 / m4a / wav などの音声ファイルをアップロードしてください",
type=["mp3", "wav", "m4a", "ogg", "flac"],
)
if uploaded_file is None:
st.info("音声ファイルをアップロードすると、ここに情報が表示されます。")
else:
ext = uploaded_file.name.split(".")[-1].lower()
file_size_mb = uploaded_file.size / (1024 * 1024)
st.write(f"- ファイル名: `{uploaded_file.name}`(約 {file_size_mb:.2f} MB)")
st.audio(uploaded_file, format=f"audio/{ext}")
st.session_state["last_filename"] = uploaded_file.name
st.markdown("### 文字起こし")
# ===== 文字起こしボタンを押したときだけ「計算」を実行し、結果は session_state に保存 =====
if uploaded_file is not None and st.button("文字起こし開始", type="primary"):
progress_text = st.empty()
progress_bar = st.progress(0)
try:
diarization_result = None
labeled_segments = None
# 1. 一時ファイル作成
progress_text.text("一時ファイルを作成中...")
progress_bar.progress(10)
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{ext}") as tmp:
tmp.write(uploaded_file.getvalue())
temp_path = tmp.name
# 2. Whisper モデルロード
progress_text.text(f"Whisper モデル `{model_name}` をロード中...")
load_start = time.time()
model = load_whisper_model(model_name)
load_end = time.time()
progress_bar.progress(40)
progress_text.text(
f"モデルロード完了({load_end - load_start:.2f} 秒)。文字起こしを開始します..."
)
# 3. Whisper で文字起こし
transcribe_start = time.time()
progress_bar.progress(50)
transcribe_options = {}
if language_code:
transcribe_options["language"] = language_code
result = model.transcribe(temp_path, **transcribe_options)
transcribe_end = time.time()
progress_bar.progress(80)
progress_text.text("文字起こしが完了しました。必要に応じて話者分離を実行します...")
total_time = transcribe_end - load_start
transcribe_time = transcribe_end - transcribe_start
# 4. 話者分離(オプション・ローカルモデル)
if use_diarization and HAVE_PYANNOTE and HAVE_TORCHAUDIO:
try:
progress_text.text("話者分離を実行中(pyannote.audio + torchaudio)...")
diar_start = time.time()
pipeline = load_diarization_pipeline()
waveform, sr = torchaudio.load(temp_path)
diarization_result = pipeline(
{"waveform": waveform, "sample_rate": sr}
)
diar_end = time.time()
progress_bar.progress(95)
progress_text.text(
f"話者分離完了(約 {diar_end - diar_start:.2f} 秒)。結果をマージしています..."
)
segments = result.get("segments", [])
if segments:
labeled_segments = attach_speakers_to_whisper_segments(
segments, diarization_result
)
except Exception as e:
st.warning(
"話者分離中にエラーが発生しました。\n"
"今回は話者分離をスキップして、通常の文字起こしのみを表示します。\n"
f"詳細: {e}"
)
progress_bar.progress(100)
progress_text.text("処理が完了しました。結果を表示しています...")
# ===== 結果を session_state に保存 =====
text = result.get("text", "") or ""
st.session_state["transcript_text"] = text
st.session_state["transcript_meta"] = {
"transcribe_time": transcribe_time,
"total_time": total_time,
}
st.session_state["labeled_segments"] = labeled_segments
st.success(
f"文字起こし完了(文字起こし処理: {transcribe_time:.2f} 秒 / 合計: {total_time:.2f} 秒)"
)
except Exception as e:
progress_bar.progress(0)
progress_text.empty()
st.error(f"エラーが発生しました: {e}")
finally:
if "temp_path" in locals() and os.path.exists(temp_path):
try:
os.unlink(temp_path)
except OSError:
pass
# ===== ここから下は「session_state に残っている結果」を毎回表示するだけ =====
meta = st.session_state.get("transcript_meta", {})
transcript_text = st.session_state.get("transcript_text", "")
labeled_segments = st.session_state.get("labeled_segments", None)
last_filename = st.session_state.get("last_filename", "result")
if transcript_text:
# メタ情報表示(あれば)
if meta:
st.info(
f"前回の文字起こし結果(処理時間: "
f"{meta.get('transcribe_time', 0):.2f} 秒 / "
f"合計: {meta.get('total_time', 0):.2f} 秒)"
)
st.markdown("### 結果(テキスト全文)")
st.text_area(
"文字起こし結果",
value=transcript_text,
height=250,
key="full_text_area",
)
st.download_button(
label="テキストをダウンロード",
data=transcript_text,
file_name=f"{os.path.splitext(last_filename)[0]}_transcript.txt",
mime="text/plain",
key="download_full_text",
)
# ===== 話者分離結果の表示 =====
if labeled_segments:
st.markdown("### 話者ごとの結果(簡易)")
speaker_lines = []
for seg in labeled_segments:
spk = seg.get("speaker", "UNKNOWN")
start_ts = format_timestamp(float(seg["start"]))
end_ts = format_timestamp(float(seg["end"]))
seg_text = seg.get("text", "").strip()
line = f"{spk} [{start_ts} - {end_ts}] {seg_text}"
speaker_lines.append(line)
speaker_text = "\n".join(speaker_lines)
st.text_area(
"話者ラベル付きテキスト",
value=speaker_text,
height=300,
key="speaker_text_area",
)
st.download_button(
label="話者ラベル付きテキストをダウンロード",
data=speaker_text,
file_name=f"{os.path.splitext(last_filename)[0]}_speaker.txt",
mime="text/plain",
key="download_speaker_text",
)
elif use_diarization and not HAVE_PYANNOTE:
st.warning(
"pyannote.audio がインストールされていないため、話者分離は実行されませんでした。"
)
elif use_diarization and not HAVE_TORCHAUDIO:
st.warning(
"torchaudio がインストールされていないため、話者分離は実行されませんでした。"
)
if __name__ == "__main__":
main()
動作テスト
サンプル結果ですが、非対応GPUだった為、CPUのみで計算しているようでしたが、5分、1700文字、100行程度の音声ファイルで2分30秒程度でした。Whisperのモデル細部はbaseで計測しました。
ad




2025-12-28
pytorchインストール手順を削除、その1のページへインストールを統合。
modelsの階層を変更